k-means可能是最知名的聚类算法,它是很多入门级数据科学和机器学习课程的内容。下面来回顾一下。
算法步骤
k-means算法的原理很简单,下面来回顾一下算法步骤。
- 首先,我们选择一些类/组,并随机初始化它们各自的中心点。为了算出要使用的类的数量,最好快速查看一下数据,并尝试识别不同的组。中心点是与每个数据点向量长度相同的位置,在上图中是「X」。
- 通过计算数据点与每个组中心之间的距离来对每个点进行分类,然后将该点归类于组中心与其最接近的组中。
- 根据这些分类点,我们利用组中所有向量的均值来重新计算组中心。
- 重复这些步骤来进行一定数量的迭代,或者直到组中心在每次迭代后的变化不大。你也可以选择随机初始化组中心几次,然后选择看起来提供了最佳结果的运行。
优点与缺点
K-means的优势在于速度快,因为我们真正在做的是计算点和组中心之间的距离:非常少的计算!因此它具有线性复杂度 O(n)。
另一方面,K-Means 有一些缺点。首先,你必须选择有多少组/类。这并不总是仔细的,并且理想情况下,我们希望聚类算法能够帮我们解决分多少类的问题,因为它的目的是从数据中获得一些见解。K-means 也从随机选择的聚类中心开始,所以它可能在不同的算法中产生不同的聚类结果。因此,结果可能不可重复并缺乏一致性。其他聚类方法更加一致。
代码
1 | import numpy as np |
生成数据
1 | # 造数据 |
1 | cluster_x = np.random.randint(0, 8, 3).tolist() |
1 | fig = plt.figure(1, figsize=(7, 7)) |

1 | # 计算欧氏距离 |
1 | plt.ion() |
运行后,可以看到下图的聚类过程(如果jupyter notebook上无法显示,则到IDE上运行)。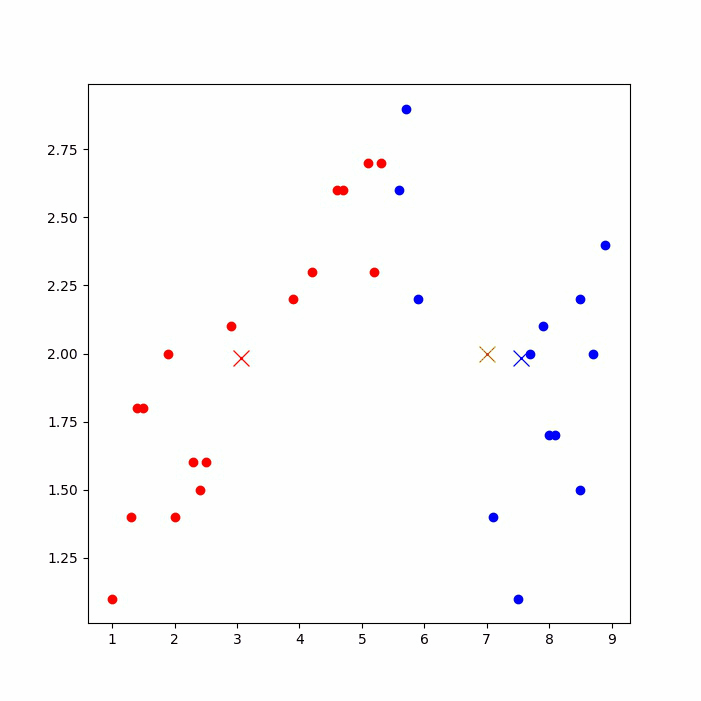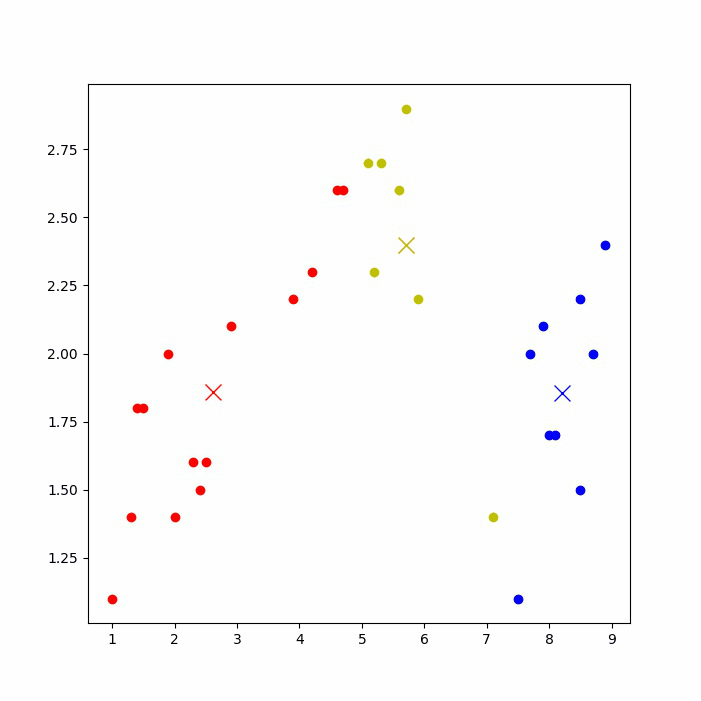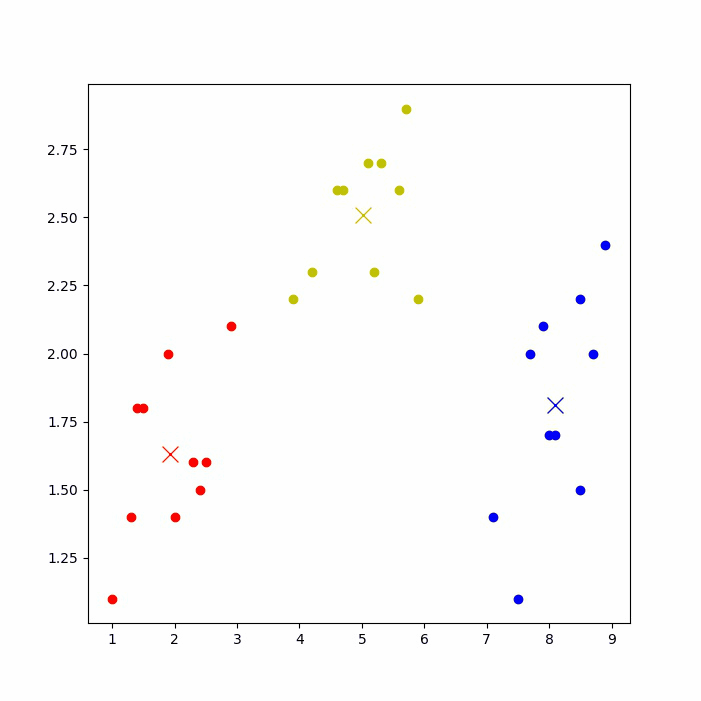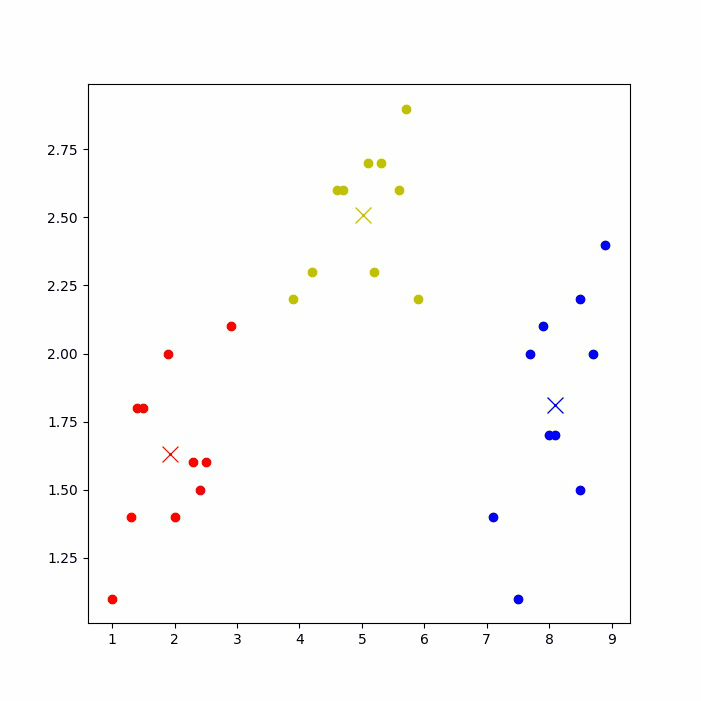
再次运行代码,由于初始点选取的随机性,可能会得到不一样的聚类结果,如下图: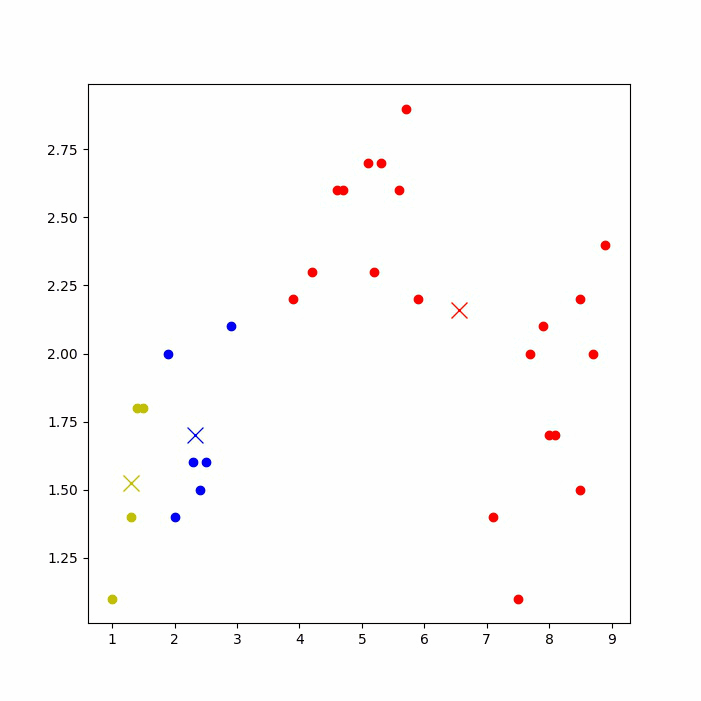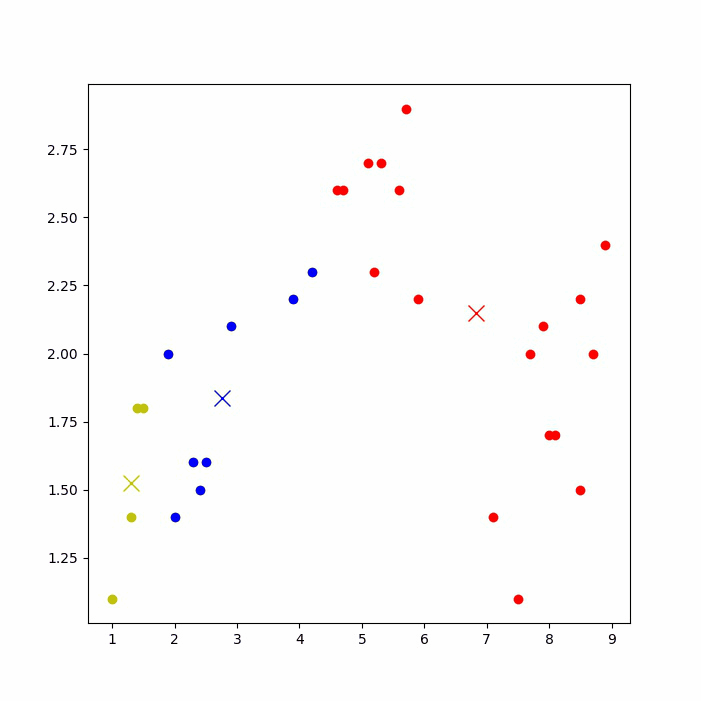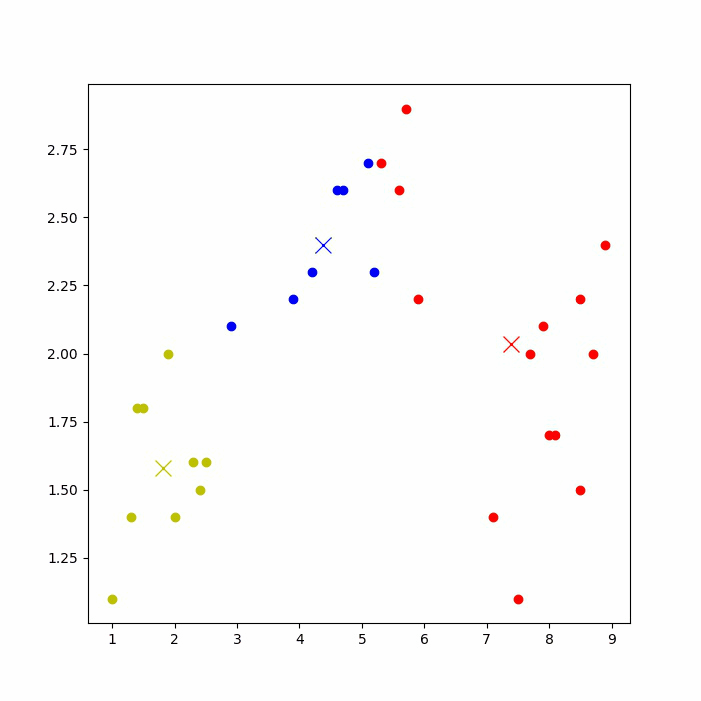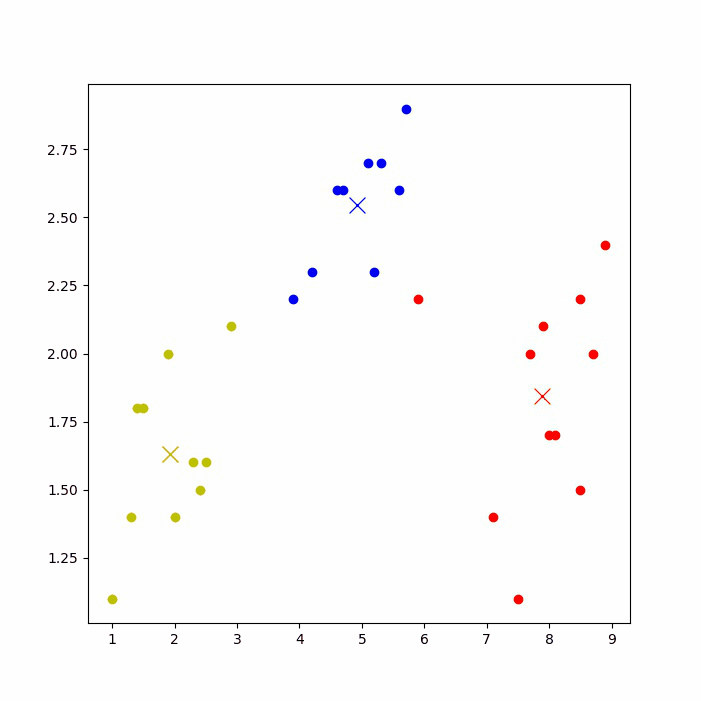
enjoy it!
参考资料:聚类算法合集
代码:https://github.com/nanyoullm/cluster-algorithm/tree/master/kmeans
