DBSCAN是一种基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
算法步骤
我们来看一下算法的步骤:
- DBSCAN从一个没有被访问过的任意起始数据点开始。这个点的邻域是用距离 ε(ε 距离内的所有点都是邻域点)提取的。
- 如果在这个邻域内有足够数量的点(根据 minPoints),则聚类过程开始,并且当前数据点成为新簇的第一个点。否则,该点将会被标记为噪声(稍后这个噪声点可能仍会成为聚类的一部分)。在这两种情况下,该点都被标记为「已访问」。
- 对于新簇中的第一个点,其 ε 距离邻域内的点也成为该簇的一部分。这个使所有 ε 邻域内的点都属于同一个簇的过程将对所有刚刚添加到簇中的新点进行重复。
- 重复步骤 2 和 3,直到簇中所有的点都被确定,即簇的 ε 邻域内的所有点都被访问和标记过。
- 一旦我们完成了当前的簇,一个新的未访问点将被检索和处理,导致发现另一个簇或噪声。重复这个过程直到所有的点被标记为已访问。由于所有点都已经被访问,所以每个点都属于某个簇或噪声。
代码
我们先看下数据(二维)的分布。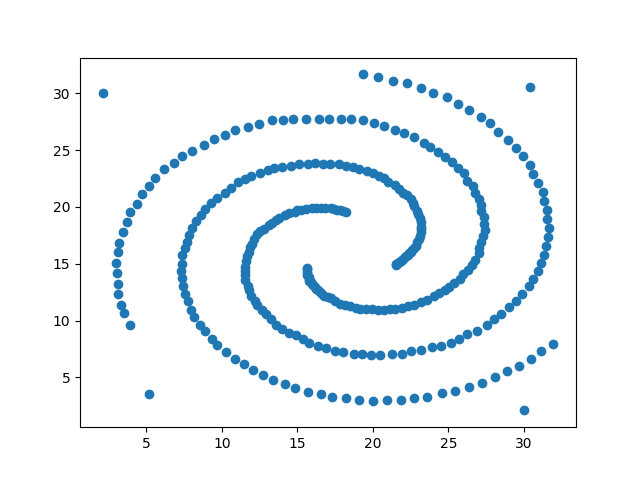
可以看到有3条螺旋状的数据序列,显然利用DBSCAN方法可以将这3条数据区分开来。另外,在坐标的四个顶点附近还有4个噪声点。1
2
3import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
定义簇对象,为简单起见,假设数据为二维。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 簇对象
class Cluster(object):
def __init__(self, name):
self.name = name
self.points = []
# 判断该点是否在簇内
def has_point(self, point):
return point in self.points
# 添加点到该簇
def add_point(self, point):
self.points.append(point)
# 获取该簇所有点的x坐标
def get_point_x(self):
return list(map(lambda x: x[0], self.points))
# 获取该簇所有点的y坐标
def get_point_y(self):
return list(map(lambda x: x[1], self.points))
# 簇内总点数
def point_count(self):
return len(self.points)
定义DBScan对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88# DBScan对象
class DBScan(object):
def __init__(self, min_points, eps):
# 设置最小满足连续簇的点数
self.min_points = min_points
# 设置定义为邻居的最大距离
self.eps = eps
self.visited = []
self.cluster = []
self.num_cluster = 0
self.data = []
self.color = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
# 计算两点之间的欧氏距离
def cal_distance(p1, p2):
return np.sqrt(pow(p1[0] - p2[0], 2) + pow(p1[1] - p2[1], 2))
# 寻找邻居点
def find_neighbours(self, point):
neighbours = []
for p in self.data:
if p != point and self.cal_distance(p, point) <= self.eps:
neighbours.append(p)
return neighbours
# 获取指定名称的簇对象
def get_cluster(self, name):
for cluster in self.cluster:
if cluster.name == name:
return cluster
raise ValueError('no such cluster named {}'.format(name))
# 发展簇成员
def expand_cluster(self, cluster, neighbours):
for point in neighbours:
if point not in self.visited:
self.visited.append(point)
# 寻找邻居的邻居
new_neighbours = self.find_neighbours(point)
if len(new_neighbours) >= self.min_points:
for nnp in new_neighbours:
if nnp not in neighbours:
neighbours.append(nnp)
# 如果该点没有被其他簇据为己有,自己之前也没发展过,那么就收了它
for other in self.cluster:
if not other.has_point(point):
if not cluster.has_point(point):
cluster.add_point(point)
# 发展结束
self.cluster.append(cluster)
# 运行dbscan算法
def run_dbscan(self, data):
self.data = data
fig = plt.figure()
ax = fig.add_subplot(111)
noise = Cluster('Noise')
self.cluster.append(noise)
for point in self.data:
if point not in self.visited:
self.visited.append(point)
neighbours = self.find_neighbours(point)
if len(neighbours) < self.min_points:
noise.add_point(point)
else:
# 到了这里说明发现了一个新的簇
cluster_name = 'Cluster_{}'.format(self.num_cluster)
new_cluster = Cluster(cluster_name)
self.num_cluster += 1
new_cluster.add_point(point)
# 发展这个簇成员
self.expand_cluster(new_cluster, neighbours)
# 画出散点图
ax.scatter(new_cluster.get_point_x(), new_cluster.get_point_y(),
c=self.color[self.num_cluster], marker='o', label=cluster_name)
if noise.point_count() > 0:
ax.scatter(noise.get_point_x(), noise.get_point_y(),
c=self.color[-1], marker='x', label='Noise')
ax.legend(loc='best')
plt.title('DBScan')
plt.show()
1 | if __name__ == '__main__': |
运行后,可以看到聚类结果如下图(如果jupyter notebook上无法显示,则到IDE上运行)。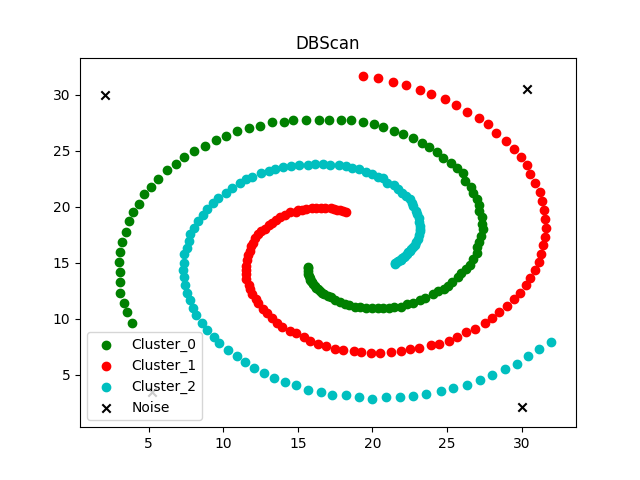
可以看出,程序成功识别出了3条密度连续的数据,以及4个噪声点数据。
enjoy it!
参考资料:聚类算法合集
代码:https://github.com/nanyoullm/cluster-algorithm/tree/master/dbscan
