PyTorch 由 Adam Paszke、Sam Gross 与 Soumith Chintala 等人牵头开发,其成员来自 Facebook FAIR 和其他多家实验室。它是一种 Python 优先的深度学习框架,在今年 1 月被开源,提供了两种高层面的功能:使用强大的 GPU 加速的 Tensor 计算(类似 numpy)构建于基于 tape 的 autograd 系统的深度神经网络。
相比Tensorflow,博主认为pyTorch更加轻量级,接口更加友好,实现起来更快。这里是我学习官网教程后写的一些快速入门总结,欢迎参考。
Tensors
- 这里我们学习一下pyTorch的Tensors基本数据操作
1.实现一个简单的神经网络反向传播
1 | import torch |
1 | # batch size |
1 | # 正态分布随机定义训练数据 |
1 | # 可训练参数定义 |
1 | learning_rate = 1e-6 |
- 我们看一下反向传播的计算步骤,图片截自课程UFLDL

1 | for i in range(100): |
step: 0, loss: 30453627.075980008
step: 10, loss: 96118006.45569089
step: 20, loss: 6532067.706399638
step: 30, loss: 334688.0713296371
step: 40, loss: 115934.43128277308
step: 50, loss: 54652.07092030634
step: 60, loss: 26871.274211959113
step: 70, loss: 13525.872293335078
step: 80, loss: 6936.796671634329
step: 90, loss: 3612.269671562068
- 以上对pyTorch的Tensor操作有一个简单认识,如mm点乘操作。
2.自动求导
- pyTorch有一个重要的对象,就是Variable,将Tensor转化为Variable后,pyTorch可以根据我们自定义的公式或者网络结构,实现自动梯度求导;
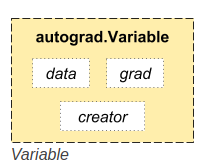
- 上图是Variable的重要属性。对于一个Variable对象,.data可以获得原始的tensor对象;当计算梯度后,该变量的梯度可以累计到,grad;
- 我们先感受一下这个强大的功能,很真实;
1 | from torch.autograd import Variable |
1 1
1 1
[torch.FloatTensor of size 2x2]
- 现在我们自定义一个$y$,$y=x+2$
- 自定义一个$z$,$z=3*y^{2}$
- $out=\frac{1}{4}*z$
1 | y = x + 2 |
Variable containing:
3 3
3 3
[torch.FloatTensor of size 2x2]
Variable containing:
27 27
27 27
[torch.FloatTensor of size 2x2]
Variable containing:
27
[torch.FloatTensor of size 1]
- 现在我们对out进行反向求导;
- $out$对$x$的求导结果为:$\frac{3}{2}*(x+2)$,$x$取矩阵中对应的值1,故为4.5
1 | out.backward() |
Variable containing:
4.5000 4.5000
4.5000 4.5000
[torch.FloatTensor of size 2x2]
None
- 请注意上面的结果,在out进行反向计算后,我们可以看到关系链最前段的x变量的梯度,但是我们无法看到y的梯度,返回了一个None,这是为什么呢?这里有一个合理的解释pytorch_hook
- pyTorch的开发者解释道:中间变量在完成了自身的反向传播使命后会被释放掉,因此我们想看中间变量的梯度,可以为其添加一个钩(hook);直观理解,就是在这个中间变量完成反向传播计算的时候,再额外完成另一些任务,我们修改代码如下。
1 | # 用于记录y变量的梯度 |
Variable containing:
4.5000 4.5000
4.5000 4.5000
[torch.FloatTensor of size 2x2]
[Variable containing:
4.5000 4.5000
4.5000 4.5000
[torch.FloatTensor of size 2x2]
]
- 有公式我们知道,x和y的梯度应该是一样的;
同时我们再思考一下,这个hook还有什么用呢?
当你训练了一个网络,想提取中间层的参数或者CNN中的feature map时,hook就可以排上用场啦!
了解了Variable,现在我们使用Variable来重新实现上面的反向求导;
1 | x = torch.randn(batch_size, input_size).type(torch.FloatTensor) |
1 | for i in range(100): |
step: 0, loss: 30182246.0
step: 10, loss: 110130184.0
step: 20, loss: 6302686.0
step: 30, loss: 294130.6875
step: 40, loss: 114886.25
step: 50, loss: 55154.7421875
step: 60, loss: 27675.9296875
step: 70, loss: 14308.21875
step: 80, loss: 7567.3125
step: 90, loss: 4075.057373046875
- 前面我们说到,Variable的grad是会累计的,所以每次计算之后需要清零;
- 另外Variable.data可以获取到tensor对象;
- 通过自动计算梯度,我们可以免去自行推公式的繁琐,并且保证不会出错;
Tensor VS Numpy
pyTorch内设置了tensor和numpy的array的转换桥梁
1 | import numpy as np |
1
2
3
[torch.LongTensor of size 3]
1 | # tensor to array |
[[ 1. 1.]
[ 1. 1.]]
自定义autograd函数
- pytorch里,用户可以自定义autograd函数,可以参考autograd
