这里介绍一下评分卡的开发的常规操作。它实际上是一个数据科学的课题,流程上有很多与机器学习实际问题相同的地方,但是它又具有其特别之处,如具有时间周期性,特征业务可解释性的需求等…让我们来认识一下吧!
评分卡的开发过程
1. 标准评分卡
1.1. 评分卡的类型和目的
信用评分卡主要分为两类:
- 申请评分卡,对新贷款申请进行筛选并判断其违约风险;(我们说的贷前阶段的A卡)
- 行为评分卡,对审批通过的贷款账户进行覆盖整个贷款周期的管理;(我们说的贷中阶段的B卡)
通常,申请评分卡被用来对新贷款申请进行一次性信用评分;而行为评分卡被用来对已经通过审批并进入到执行阶段的账户,即已经进行了一定交易的账户,进行信用评分。
两种评分卡的开发过程都遵循同样的基本方法,主要差别在于:行为评分卡要比申请评分卡更为准确,因为行为评分卡基于的数据要更多,观察周期也可以更长。
1.2. 标准评分卡格式


1.3. 评分卡开发流程
- 该流程的主要步骤包括:
- 问题准备;
- 数据获取和整合;
- 探索性数据分析与数据描述;
- 数据准备;
- 变量选择;
- 模型开发;
- 模型验证和评价;
- 评分卡创建和刻度;
- 评分卡实施;
- 监测和报告;
- 可以用一下流程图表示:
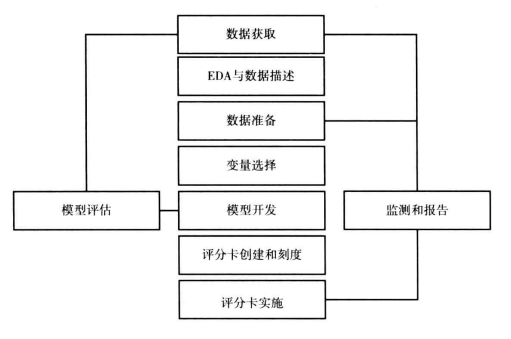
- 实际上,这个流程和一般性的数据科学课题的步骤是保持一致的。
- 1就是我们对应业务场景需要解决的问题,比如我们要做逾期客户的模型,我们是否需要针对某一渠道来源的客户?逾期3、30还是90天以上?选定的逾期客户是首次逾期的还是多次逾期的?我们需要具有多久表现期的用户?等等。我们需要严谨得定义y变量;
- 2-4可以对于对数据探索和特征工程,这也是整个评分卡开发过程中最耗时的地方;
- 5变量选择,在个人金融信用评分卡开发过程中,普遍选取15个左右的变量,而且非常重要的一点是,这些变量必须具备业务解释性。如果我们做出了一个还不错的变量,但是我们无法解释这个变量具有什么样的业务含义,大的值表示什么,小的值表示什么,那么这样的变量即使具有不错的区分度,那么也很有可能被我们舍弃,这点是有别与一般的数据科学课题的。再次强调,目前的个人金融信用评分卡十分注重业务解释性;常用的变量选择方法有IV选取法;
- 6-7,标准评分卡是局域logistic回归模型,在完成模型开发后,我们还需要进行模型的验证,包括ks值和模型在不同时间段表现出来的稳健性;
- 8评分卡创建和刻度是评分卡开发中十分重要的一个环节,就是我们如何根据用户的违约概率生成其对应的信用评分?这部分还是不少干货的,我也会后续进行详解。
