我们身处于大数据的一个起步时代,作为一个码农,掌握大数据计算平台的使用还是必须的。Apache Spark作为近年来最流行的大数据开源项目,可以说是占据了大小互联网的生产环境,是一个“快如闪电的集群计算”工具。关于Spark的介绍我也不多说啦,可以看看官网Spark。这里需要说明的是,博主并没有阅读过Spark的源码,对Spark较多的是停留在应用层面。博主对Spark的应用主要是在公司的大小日常项目中,目前接触过的最大数据量的项目为联通集团的数据挖掘项目。
博客的内容很多是给自己回顾所涉及的点,不是很完善。所述之处如有错误,还请及时指出。
集群样貌
我们看一下spark任务提交集群后,各节点的部署图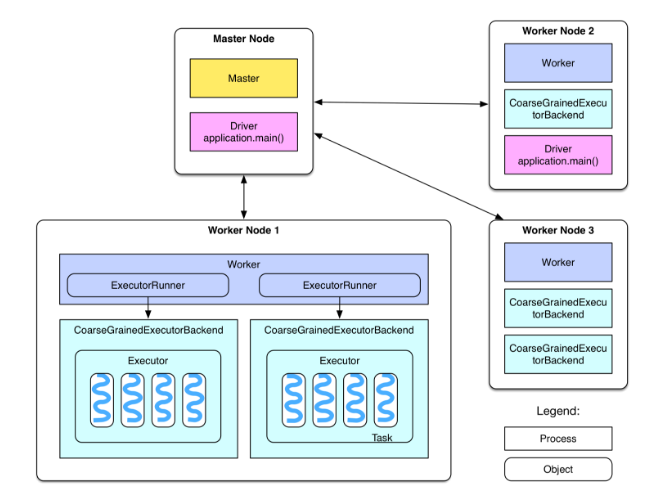
图中可以看到:
- spark集群分为Master节点和Worker节点;
- Master节点有Master进程,负责管理全部的Worker节点;
- Worker节点有Worker进程,管理本node下的executers并负责与Master节点通信;
- 每个Worker上有多个ExecutorBackend进程,每个对应一个Executor对象,每个对象有一个线程池,线程池里的一个线程负责一个Task,一个Task是具体执行任务的一个工作单元,由用户在提交任务的时候设置资源参数executor.core定义;
- Driver是具体跑用户自己写的Spark程序进程,如果是YARN集群部署,那么Driver就会被调度到Worker上运行;
RDD
rdd是spark任务中用到最多的数据结构,rdd的全程是Resilient Distributed Datasets,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,是将数据分布式得存储在各台机器中,并能控制数据的分区。那么,我们可以对rdd做那些操作呢?可以分为两类
transform
官方解释:Return a MappedRDD[U] by applying function f to each element.就是对每个数据进行改造和转换,从一个rdd生成一个新的rdd.
spark中,针对rdd的transform操作有:
- map
- filter
- sample
- groupByKey
…
等等
action
官方解释:有一个rdd得到一个值,比如说统计rdd里的数据总数。spark中,针对rdd的action操作有:
- count
- collect
- saveXXXX
… 等等
DAG
DAG是spark中的一个重要概念。我们在用spark进行对源数据进行处理并最后得到我们想要的结果的过程,实际上是一个若干tranform的变换和合并的组合,可以看成一个流程图,这个流程图被spark抽象为DAG,即Directed Acyclic Graph。在生产集群上,我们可以通过SparkUI看到每个运行任务的DAG图.
Job
job的官方定义:A parallel computation consisting of multiple tasks that
gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.
一个action操作对应一个job,spark程序中,只有触发了action操作后,整个dag才能建立起来,如果只是一堆transform操作而没有action操作,那么spark是不会有任何数据操作的。以数字统计为例,job的逻辑执行图可如下所示:
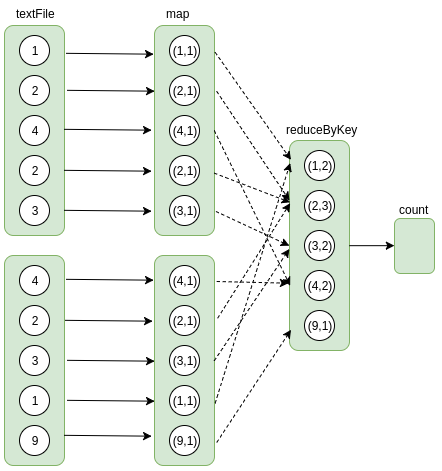
这个job通过count操作触发。
Stage
stage的官方定义:Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs.
一个job可以拆分成若干个stage,每个stage执行一些计算,产生一些中间结果。它们的目的是最终生成这个Job的计算结果。而每个Stage是一个task set,包含若干个task。Task是Spark中最小的工作单元,在一个executor上完成一个特定的事情。那么如何划分stage呢?这里我们要了解一下spark中的shuffle。
shuffle
shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
rdd transform依赖关系
rdd在transform操作后,前面涉及到的rdd成为parent,我们可以从下图中看到前后的依赖关系: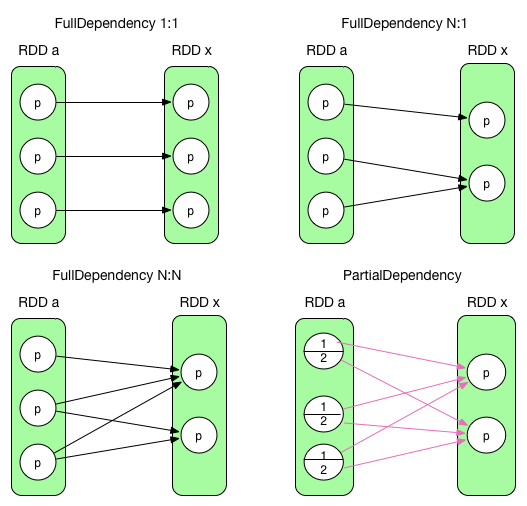
前三个是完全依赖,RDD x 中的 partition 与 parent RDD 中的 partition/partitions 完全相关。最后一个是部分依赖,RDD x 中的 partition 只与 parent RDD 中的 partition 一部分数据相关,另一部分数据与 RDD x 中的其他 partition 相关。完全依赖被称为 NarrowDependency,部分依赖被称为 ShuffleDependency。最后一个会出发shuffle。
回到刚刚的问题,如何划分stage呢?从后往前推算,遇到ShuffleDependency就断开,遇到NarrowDependency就将其加入该stage。每个stage里的task数目由该stage最后一个rdd中的partition个数决定。
参考资料:https://spark-internals.books.yourtion.com/index.html
