相信对kaggle有一定了解和初入数据领域的同学们都做过titanic竞赛。titanic竞赛是一个分类问题,参赛同学通过对训练集中每位乘客的年龄、票等级、家庭信息等情况进行分析,判断测试集中每位乘客的存活情况,最后使用accuracy作为标准进行评价。虽然这是一个入门的竞赛题,网上也非常多的参考,但博主还是有很认真的做(前前后后花了1个多月的时间,虽然成绩还是有点不满意),最高成绩是排在Top6%左右。
- 泰坦尼克灾难是kaggle的经典题目,这里结合我之前对这个题目的经验和后续参考其他大牛的分析方法,做一个汇总,希望能达到Top3%的水平。
- 之前尝试过对空值的进行处理(包括对年龄字段进行拟合),并且做了不少的特征工程,得到的结果往往是在cross validation中可以获得约0.85左右的得分,但是在test集中降到0.76左右。
- 后来参考过了其他同学的一些建议,发现这是一个过拟合的现象,train集和test集有一定的偏差,所以还是需要做一些特征筛选。
- 在调研过程中,有一位大牛通过对age、freq(ticket、fare和cabin的)、familysize对乘客进行分群,然后结合pclass和sex的条件存活概率计算log likelihood值,最后针对不同的群,对对应的log likelihood进行加权或惩罚,最后仅使用这一个特征进行预测,预测结果在样本内验证集上约0.83左右的分值,在测试集上也可以达到约0.82左右的分值,泛化效果很好。原版:https://www.kaggle.com/pliptor/divide-and-conquer-0-82296 python版:https://www.kaggle.com/krasserm/divide-and-conquer-in-python-0-82296
- 另一位做了很多和我之前类似的特征工程,但是做了特征选择,据其文档描述也达到了0.81左右的分数,
分析步骤:
- 数据基本概况
- 空值处理
- 特征工程
1 | import pandas as pd |
数据基本概况
1 | train = pd.read_csv('train.csv') |
以下是官方提供的数据维度解释
- survival Survival/y变量 0 = No, 1 = Yes
- pclass Ticket class/船票等级 1 = 1st, 2 = 2nd, 3 = 3rd
- sex Sex/性别
- Age Age in years/年龄
- sibsp # of siblings / spouses aboard the Titanic/同船的同胞兄弟和配偶数
- parch # of parents / children aboard the Titanic/同船的子女和父母数
- ticket Ticket number/ 票号
- fare Passenger fare/ 费用(后经调研,为家庭总费用)
- cabin Cabin number/ 船舱号
- embarked Port of Embarkation/登船的港口
1 | # 删除离群点 |
1 | def show_count_ratio(data, x, y, xsize, ysize): |
1 | combined = pd.concat([train, test], axis=0, ignore_index=True) |
1 | print(u'空值情况') |
空值情况
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
- Age字段缺失170,如果进行拟合可能会变成噪声,可以构造是否有年龄这一特征,同时对有年龄的乘客中进行一些分析。
- Cabin字段缺失太多,暂时不做填充
- Embarked字段可以用多数值填补
数据探索&特征工程
Age & Pclass
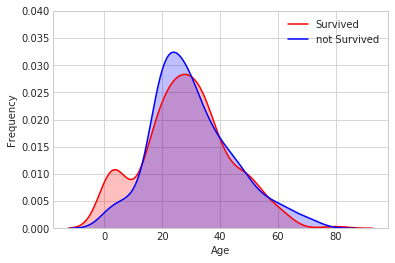
- 看下0/1乘客的年龄分布,可以发现14岁一下的乘客的存活率相对较高
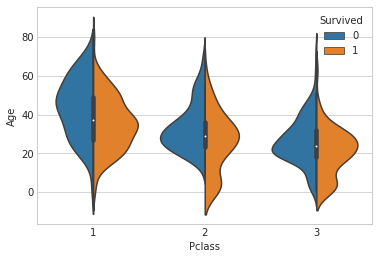
- 结合pclass和sex条件下看年龄的分布
- 又可以发现,pclass为2和3下,年龄小于14的乘客存活率相对其他更高
- 结合以上观点,针对p2和p3的年龄小于14的乘客做做文章
1 | g = sns.kdeplot(train[(train.Survived==1)&(train['Age'].notnull())]['Age'], |
(0, 0.04)
1 | sns.violinplot(data=train, x='Pclass', y='Age', hue='Survived', split=True) |
<matplotlib.axes._subplots.AxesSubplot at 0x7f45a2a686d8>
1 | # 对于p2和p3中小于14岁的乘客打标 |
Pclass & Sex
- 看一下Pclass和Sex的条件分布
1 | g = sns.factorplot(data=combined_test, x='Pclass', y='Survived', hue='Sex', kind='bar') |
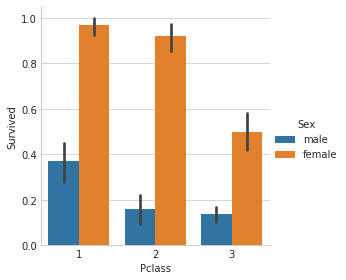
- 上图中可以发现,女乘客的存活率远高于男乘客。
- 但是p3中,女乘客的存活率,相比p1和p2低很多,接近50%左右
- 同时,p1的男乘客的存活率,相对与p2和p3高很多
- 构建log likelyhood特征
1 | # log(p/(1-p)) -> lr表达式 |
1 | survived_rate = train.groupby(['Pclass', 'Sex']).Survived.mean() |
- 看下SLogR变量与Surivived的相关性
1 | combined_test[['Survived', 'SLogR']].corr() |
| Survived | SLogR | |
|---|---|---|
| Survived | 1.000000 | 0.623948 |
| SLogR | 0.623948 | 1.000000 |
Family信息,涉及Name|Parch|SibSp
- 提取每位乘客的first name
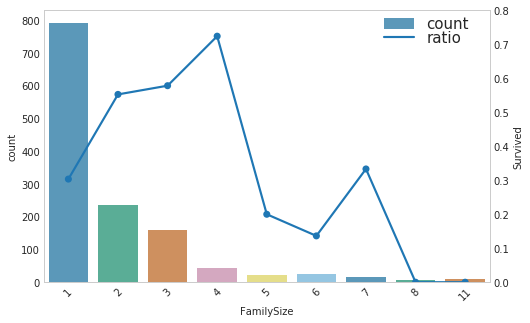
- 每位乘客的家庭人数
1 | def first_name(name): |
1 | show_count_ratio(combined_test, 'FamilySize', 'Survived', 8, 5) |
Frequency,看下FirstName|Fare|Ticket|Cabin出现频次
1 | for column in ['FirstName','Fare','Ticket','Cabin']: |
1 | def TicketFreqLevel(x): |
1 | show_count_ratio(combined_test, 'TicketFreqLevel', 'Survived', 8, 5) |
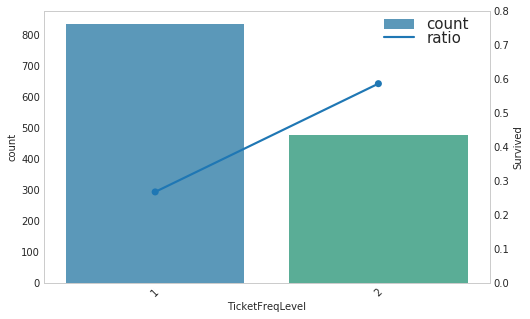
1 | combined_test[['Survived', 'TicketFreqLevel']].corr() |
| Survived | TicketFreqLevel | |
|---|---|---|
| Survived | 1.000000 | 0.315591 |
| TicketFreqLevel | 0.315591 | 1.000000 |
- 下图是FareFreq的分布和存活概率,貌似没看出什么规律
1 | show_count_ratio(combined_test, 'CabinFreq', 'Survived', 8, 5) |
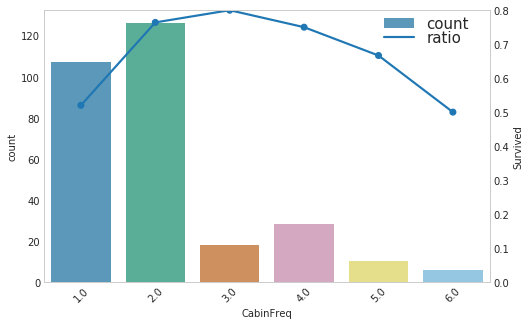
- CabinFreq的存活率普遍高,可以构造是否有Cabin值作为一个特征,看看存活情况
1 | combined_test['HasCabin'] = 0 |
1 | show_count_ratio(combined_test, 'HasCabin', 'Survived', 8, 5) |
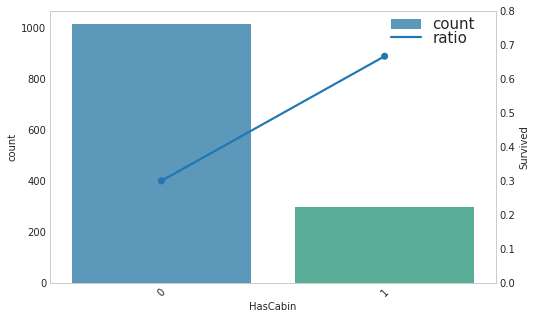
1 | combined_test[['Survived', 'HasCabin']].corr() |
| Survived | HasCabin | |
|---|---|---|
| Survived | 1.000000 | 0.316912 |
| HasCabin | 0.316912 | 1.000000 |
- 对于FareFreq没有太明显的规律,不如直接看一下Fare的分布
- test中的Fare有一个空值,用中位数填充
1 | combined_test.loc[combined_test['Fare'].isnull(), 'Fare'] = combined_test.Fare.median() |
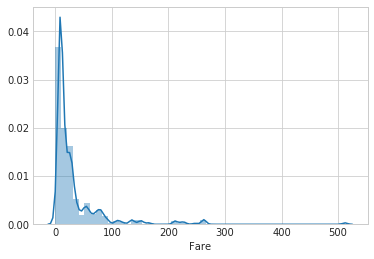
- 这个图不够平滑,取对数值看看
1 | def log_fare(x): |
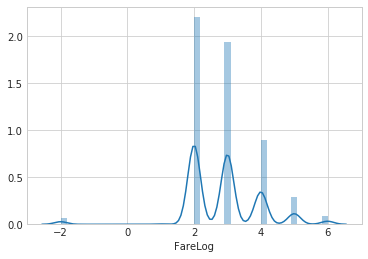
1 | show_count_ratio(combined_test, 'FareLog', 'Survived', 8, 5) |
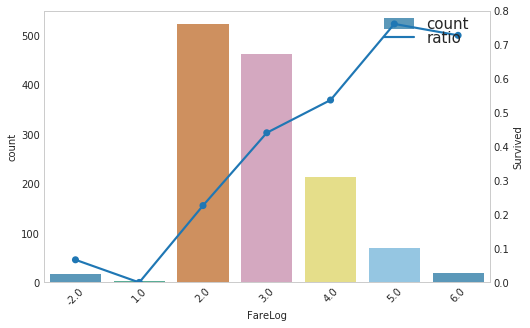
- 对Fare取了Log后,看起来是具有单调性的,干脆再进行一下合并,然后再看下分布和存活概率
1 | def log_fare_level(x): |
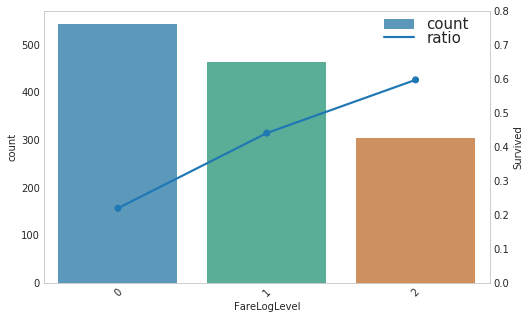
- 如上图所示,好像还可以的样子
暂时停车,回顾下现在的情况
- 缺失值情况
- 已有的特征
1 | combined_test.isnull().sum() |
Age 263
Cabin 1014
Embarked 2
Fare 0
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
Child 0
SLogR 0
FirstName 0
FamilySize 0
FirstNameFreq 0
FareFreq 1
TicketFreq 0
CabinFreq 1014
TicketFreqLevel 0
HasCabin 0
FareLog 0
FareLogLevel 0
dtype: int64
1 | fig = plt.figure(figsize=(10, 8)) |
<matplotlib.axes._subplots.AxesSubplot at 0x7f45a23f4b38>
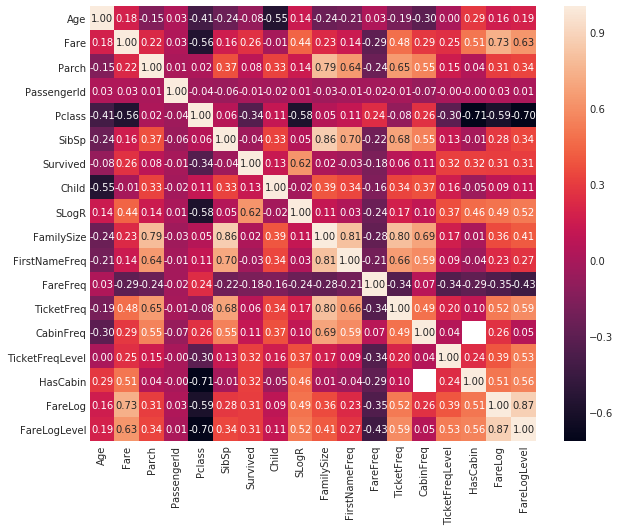
Name Title
- 每个乘客的Title可以还提取出来,如Mr,Miss等
1 | def get_title(x): |
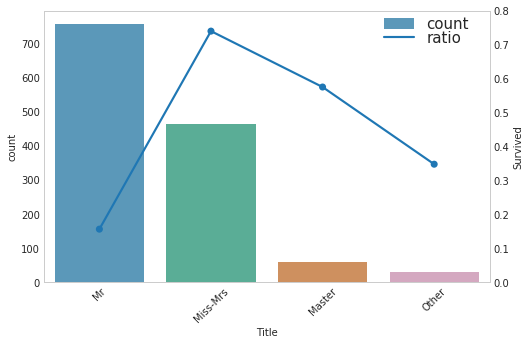
- 可以考虑将Miss-Mrs和Master归为一类,Mr和other归为一类
1 | def title_level(x): |
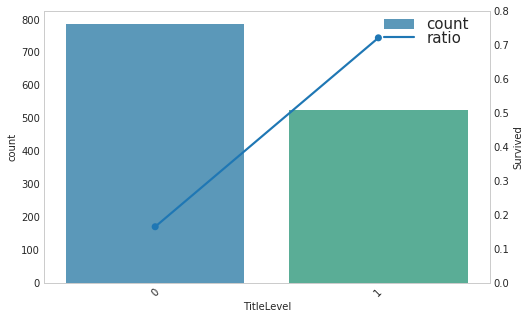
| Survived | TitleLevel | |
|---|---|---|
| Survived | 1.000000 | 0.558615 |
| TitleLevel | 0.558615 | 1.000000 |
- 嗯,感觉还阔以,再看看有什么特征可以做
1 | pd.set_option('max_column', 100) |
| Age | Cabin | Embarked | Fare | Name | Parch | PassengerId | Pclass | Sex | SibSp | Survived | Ticket | Child | SLogR | FirstName | FamilySize | FirstNameFreq | FareFreq | TicketFreq | CabinFreq | TicketFreqLevel | HasCabin | FareLog | FareLogLevel | Title | TitleLevel | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22.0 | NaN | S | 7.2500 | Braund, Mr. Owen Harris | 0 | 1 | 3 | male | 1 | 0.0 | A/5 21171 | False | -1.853635 | Braund | 2 | 2 | 18.0 | 1 | NaN | 1 | 0 | 2.0 | 0 | Mr | 0 |
| 1 | 38.0 | C85 | C | 71.2833 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 0 | 2 | 1 | female | 1 | 1.0 | PC 17599 | False | 3.412247 | Cumings | 2 | 2 | 2.0 | 2 | 2.0 | 2 | 1 | 4.0 | 2 | Miss-Mrs | 1 |
| 2 | 26.0 | NaN | S | 7.9250 | Heikkinen, Miss. Laina | 0 | 3 | 3 | female | 0 | 1.0 | STON/O2. 3101282 | False | 0.000000 | Heikkinen | 1 | 1 | 23.0 | 1 | NaN | 1 | 0 | 2.0 | 0 | Miss-Mrs | 1 |
| 3 | 35.0 | C123 | S | 53.1000 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 0 | 4 | 1 | female | 1 | 1.0 | 113803 | False | 3.412247 | Futrelle | 2 | 2 | 6.0 | 2 | 2.0 | 2 | 1 | 4.0 | 2 | Miss-Mrs | 1 |
| 4 | 35.0 | NaN | S | 8.0500 | Allen, Mr. William Henry | 0 | 5 | 3 | male | 0 | 0.0 | 373450 | False | -1.853635 | Allen | 1 | 2 | 60.0 | 1 | NaN | 1 | 0 | 2.0 | 0 | Mr | 0 |
1 | x_train = combined_test[:train.shape[0]][['SLogR','TicketFreqLevel','TitleLevel','FareLogLevel']].values |
模型训练
1 | from sklearn.model_selection import GridSearchCV |
- 大致先看一下xgboost默认参数在cv集上的性能
1 | clf = xgb.XGBClassifier() |
0.82781823856542958
1 |
1 | xgb_clf = xgb.XGBClassifier() |
{'learning_rate': 0.3, 'max_depth': 2, 'n_estimators': 180, 'subsample': 0.5}
1 | rf_clf = RandomForestClassifier() |
{'max_depth': 4, 'max_features': 1, 'n_estimators': 110}
1 | gb_clf = GradientBoostingClassifier() |
{'learning_rate': 0.3, 'max_depth': 5, 'n_estimators': 90, 'subsample': 0.5}
模型融合之stacking
- sklearn没有集成stacking模块,这里建议使用mlxtend,也是一个不错的机器学习包,还支持在2维特征空间的分类效果展示模块
1 | from mlxtend.classifier import StackingClassifier |
1 | sclf.fit(x_train, y_train) |
StackingClassifier(average_probas=False,
classifiers=[XGBClassifier(base_score=0.5, colsample_bylevel=1, colsample_bytree=1,
gamma=0, learning_rate=0.3, max_delta_step=0, max_depth=2,
min_child_weight=1, missing=None, n_estimators=180, nthread=-1,
objective='binary:logistic', reg_alpha=0, reg_lambda=1,
scale_pos...imators=110, n_jobs=1, oob_score=False, random_state=None,
verbose=0, warm_start=False)],
meta_classifier=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False),
use_features_in_secondary=False, use_probas=True, verbose=0)
1 | scores.mean() |
0.80375198552231075
1 | cross_val_score(gs_xgb.best_estimator_, x_train, y_train, cv=5, scoring='accuracy').mean() |
0.81827712518711526
1 | x_test = combined_test[train.shape[0]:][['SLogR','TicketFreqLevel','TitleLevel','FareLogLevel']].values |
