ResNet残差神经网络是何凯明博士于2016年提出的,其相关论文获得了当年CVPR的best parer。计算机视觉领域中,可以证明更深的神经网络可以学习更好的特征,取得更好的识别成绩。虽然ReLU、dropout等方法减小了深层神经网络训练过程中梯度弥散的影响,训练深层的网络依然会出现退化(degradation)的情况。而ResNet的提出,使得更深层的网络得以训练。
以下内容为学习论文和参考其他资料后的简单总结,包含实现代码。
ResNet
原理
计算机视觉领域中,更深层次的神经网络可以学习到更深的特征。VGG和GoogleNet分别依靠19层、22层的网络结构在ILSVRC2014比赛中将错误率降低到了7.3、6.7。
所以,学习更好的网络是否与堆叠更多层数一样简单呢?
Is learning better networks as easy as stacking more layers?
答案是否,梯度弥散/爆炸问题依然阻碍收敛的最大障碍。虽然ReLU、dropout等方法可以缓解这个情况。当一个更深的网络开始收敛时,会出现一个称为退化(原文为degradation)的现象:深度增加,准确率开始饱和后开始迅速衰减。退化现象并不是由于过拟合所导致的,对现有性能不错的网络增加层数后获得了更高的错误率。下图中可以看到,目前的平原网络结构(论文称为“plain”)下,56层的网络与20层的网络相比,无论是在训练集上还是测试集上,其错误率都要更高。这是一个在许多数据集中都能观察到的普遍现象。
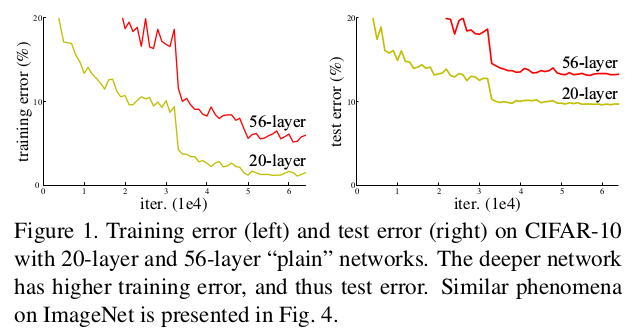
为此,论文有了这样一个想法:将增加的层作为恒等映射。deep residual learning 框架应运而生。
Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by constructionto the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model.
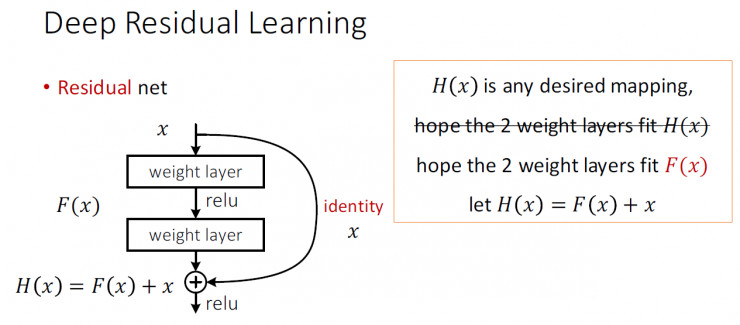
如下图平原网络中,$H(x)$是期望的映射,我们希望学习到拟合$H(x)$的两层网络参数。

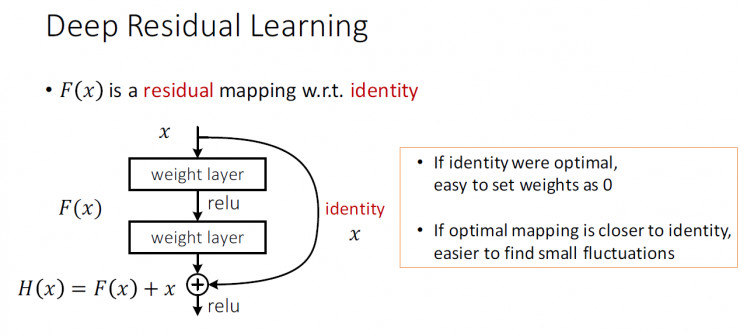
残差网络中,把$H(x)$包装一下变成下图,$H(x)=F(x)+x$,$F(x)$称为残差映射。那问题就转换为学习$F(x)$,如果$F(x)=0$,那么就是恒等映射;如果接近恒等映射,便更容易发现微小波动。
论文认为这两种表达的效果相同,但是优化的难度却并不相同,论文假设$F(x)$的优化 会比$H(x)$简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。$H(x)=F(x)+x$可以用“shortcut connections”(skipping one or more layers)形式表现,如下图中左边的网络结构.
论文就上述观点做了相关实验,具体可以参考论文resnet
大神的一点思维波动,作为学渣的我就得好生理解一番。看了论文后,实际上还是很难直观搞清楚:为什么这样就会解决退化的问题?why给了一个合理的解释,如果你熟悉反向传播的链式原理,就很容易理解。
实战
1 | import torch |
- 加载训练集图片的预处理日常操作
1 | transform = transforms.Compose([ |
- 如果没有下载数据集,设置download参数为True
1 | train_dataset = dsets.CIFAR10(root='./data/', |
- 3x3卷积
1 | def conv3x3(in_channels, out_channels, stride=1): |
- 定义残差单元 ResidualBlock
1 | class ResidualBlock(nn.Module): |
1 | class ResNet(nn.Module): |
1 | resnet = ResNet(ResidualBlock, [3, 3, 3]) |
ResNet(
(conv): Conv2d (3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(layer1): Sequential(
(0): ResidualBlock(
(conv1): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
)
(1): ResidualBlock(
(conv1): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
)
(2): ResidualBlock(
(conv1): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True)
)
)
(layer2): Sequential(
(0): ResidualBlock(
(conv1): Conv2d (16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d (16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d (32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
)
(2): ResidualBlock(
(conv1): Conv2d (32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
)
)
(layer3): Sequential(
(0): ResidualBlock(
(conv1): Conv2d (32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d (32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
(2): ResidualBlock(
(conv1): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
)
(avg_pool): AvgPool2d(kernel_size=8, stride=8, padding=0, ceil_mode=False, count_include_pad=True)
(fc): Linear(in_features=64, out_features=10)
)
1 | criterion = nn.CrossEntropyLoss() |
1 | for epoch in range(80): |
1 | correct = 0 |
