我们知道,人类思考的时候并不是从一片空白的大脑开始的(不像只有7秒记忆的鱼),而是会参考之前的经验和阅历。就像我们看悬疑片的时候,大脑会回溯之前的种种细节;阅读文章的时候,会基于对先前的理解来对文章主旨做出判断。 而这恰恰是传统的神经网络做不到的。地转轮回的RNN循环神经网络的出现解决了这个问题,它能记忆前时序的信息,其类似CNN的共享参数机制也是极大简化了网络的复杂性。由RNN进化的LSTM和GRU单元更是展现了神通广大的本领。
RNN & LSTM 及其实践
- ok,我们来看一下rnn的结构

- t时刻的输入$x_{t}$进入神经网络A后,一方面会输出一个结果$h_{t}$,同时会输出一个状态传递到下一次的循环中,作为下一次循环的自产的输入。在这个循环的过程中,A里的参数都是共享的。那么,把rnn的循环过程展开后是什么样子的呢?如下图所示:

这个结构使得它对时序性的变量有着先天性的优势,在语音识别等领域取得了一定成功。但是这个结构也存在一定的缺陷,我们来看看,以下文字摘自lstm简介
假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。也就是说,RNN在处理长期依赖问题上是具有一定的缺陷。
我们尝试用rnn做一个简单的回归预测,例子取自与莫凡大神的教程莫凡python
- 输入数据为一个sin函数,对应的预测值为cos函数;也就是用构造一个sin到cos的映射神经网络;所以,这是一个用rnn来训练sin对cos的函数映射的回归预测问题。
1 | import torch |
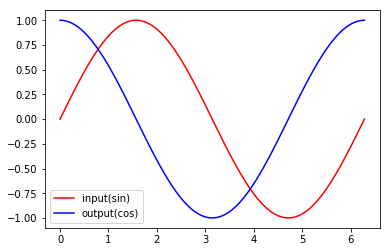
- 我们先看一哈sin和cos在xy坐标下的曲线
- 总步长数为100,每一步的长度为$\frac{2\pi}{100}$
1 | steps = np.linspace(0, np.pi * 2, 100, dtype=np.float32) |
- ok,现在我们来构建一下rnn网络
- 注意,这是一个 sequence2sequence 回归的预测,rnn的每一次循环的输出结果都是我们需要拿出来和y值计算loss的,我们可以通过forward函数里看到。
1 | class RNN(nn.Module): |
- 在xy坐标轴上,sin作为一个时序的数据,x是时序步长,y为x在每个步长上的feature值,所以feature的维度为1(即input_size),我们设定总步长数为10,每一步的长度为$\frac{2\pi}{10}$,学习率为0.01
1 | time_step = 10 |
1 | optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate) |
1 | plt.figure(1, figsize=(12, 5)) |
1 | for step in range(60): |
1 | plt.ioff() |
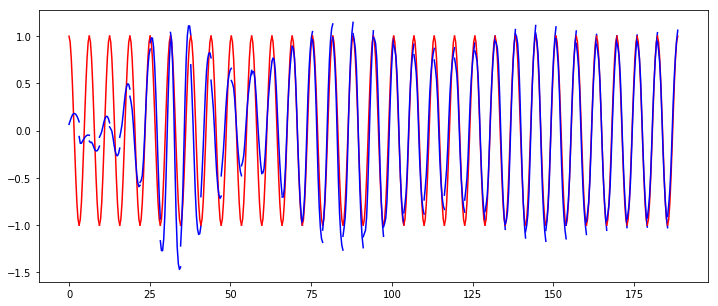
上图中,红色的曲线为用于训练数据,蓝色的曲线是预测数据,可以明显看到预测的数据有“断崖”的情况。
上面说到,RNN在处理长期依赖问题上是具有一定的缺陷,而lstm可以解决这个问题,我们看一下lstm的初貌:
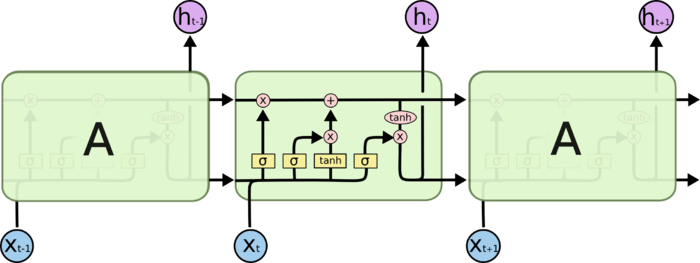
- 相比与rnn中A(我们可以称之为cell或unit)内部的简单网络结构,lstm的内部结构较为复杂,同时增加了一个关键的细胞状态
- cell内部的结构由四个门构成:
- input_gate
- forget_gate
- cell_state(gate)
- output_gate
具体每个门的公式可以参考lstm简介
ok,我们再来看一下lstm的预测效果,参数上来看lstm比rnn在每次的迭代需要多传送cell state参数
1 | class LSTM(nn.Module): |
1 | rnn = LSTM().cuda() |
1 | for step in range(60): |
1 | plt.ioff() |
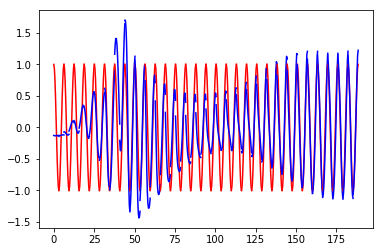
- 同样,红色的是训练数据,蓝色的是预测数据;
- 可以看出来lstm的预测结果在形状上没有单纯rnn的断崖情况,而且随着训练数据的增加趋于稳定。
