接触过深度学习的同学对手写数字识别的任务并不陌生。它一个入门的阶段,是每位初学深度学习的同学的基本学习任务。任务的目标是建立一个分类模型,对0-9的黑白手写数字图片进行识别。
以下内容是训练RNN模型,对测试集做预测,将图片的每一行作为一个time step,每一行的每一列作为一个时序step的特征。
代码
1 | import torch |
- 设置训练时需要用到的参数
- 其中注意,这里设置lstm内的隐层数为2,开始我对这个参数对网络结构的变化是有疑问的:隐层数为2到底是怎么样子的一个结构?
- 我们先回顾一下lstm结构
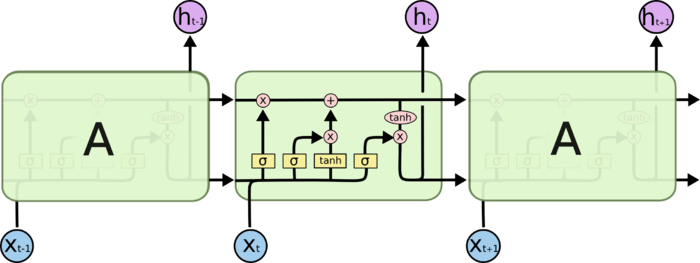
- 那么多层的lstm是什么样子呢,可以参考下图
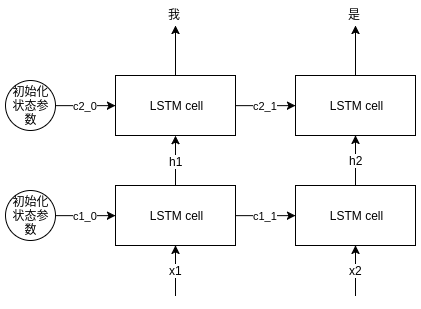
- 然而有一点我仍有疑惑,在pyTorch的lstm源码中,我们可以看到如下关于可训练参数的注释:

- 从注释中我们可以看到,两层的lstm层的 W_ii|W_if|W_ig|W_io ,(input_size x 4*hidden_size),那么问题来了;第一层lstm的输出h0、h1维度为 hidden_size,是作为第二层lstm的输入,那么为什么注释中,两层lstm的w权重都是(input_size x hidden_size)呢?这点我还没有弄清楚,还需要继续研究一下。
1 | sequence_length = 28 |
- 加载MNIST数据,走一波套路
1 | train_dataset = dsets.MNIST(root='../../data/', |
- 网络设计为 2-layers LSTM + Linear Layer
1 | class RNN(nn.Module): |
1 | rnn = RNN(input_size, hidden_size, num_layers, num_classes) |
1 | for epoch in range(num_epochs): |
epoch: 1/2, step: 100/600.0, loss: 0.39886680245399475
epoch: 1/2, step: 200/600.0, loss: 0.1921195536851883
epoch: 1/2, step: 300/600.0, loss: 0.2619330883026123
epoch: 1/2, step: 400/600.0, loss: 0.0826086699962616
epoch: 1/2, step: 500/600.0, loss: 0.2846192419528961
epoch: 1/2, step: 600/600.0, loss: 0.09135620296001434
epoch: 2/2, step: 100/600.0, loss: 0.09049663692712784
epoch: 2/2, step: 200/600.0, loss: 0.15913671255111694
epoch: 2/2, step: 300/600.0, loss: 0.03615887463092804
epoch: 2/2, step: 400/600.0, loss: 0.056473325937986374
epoch: 2/2, step: 500/600.0, loss: 0.1406131535768509
epoch: 2/2, step: 600/600.0, loss: 0.07474736869335175
1 | total = 0 |
Accuracy: 97.91%
